Datasets
We divide the dataset into two categories: the instruction dataset and the benchmark dataset.
Instruction Data
LAMM
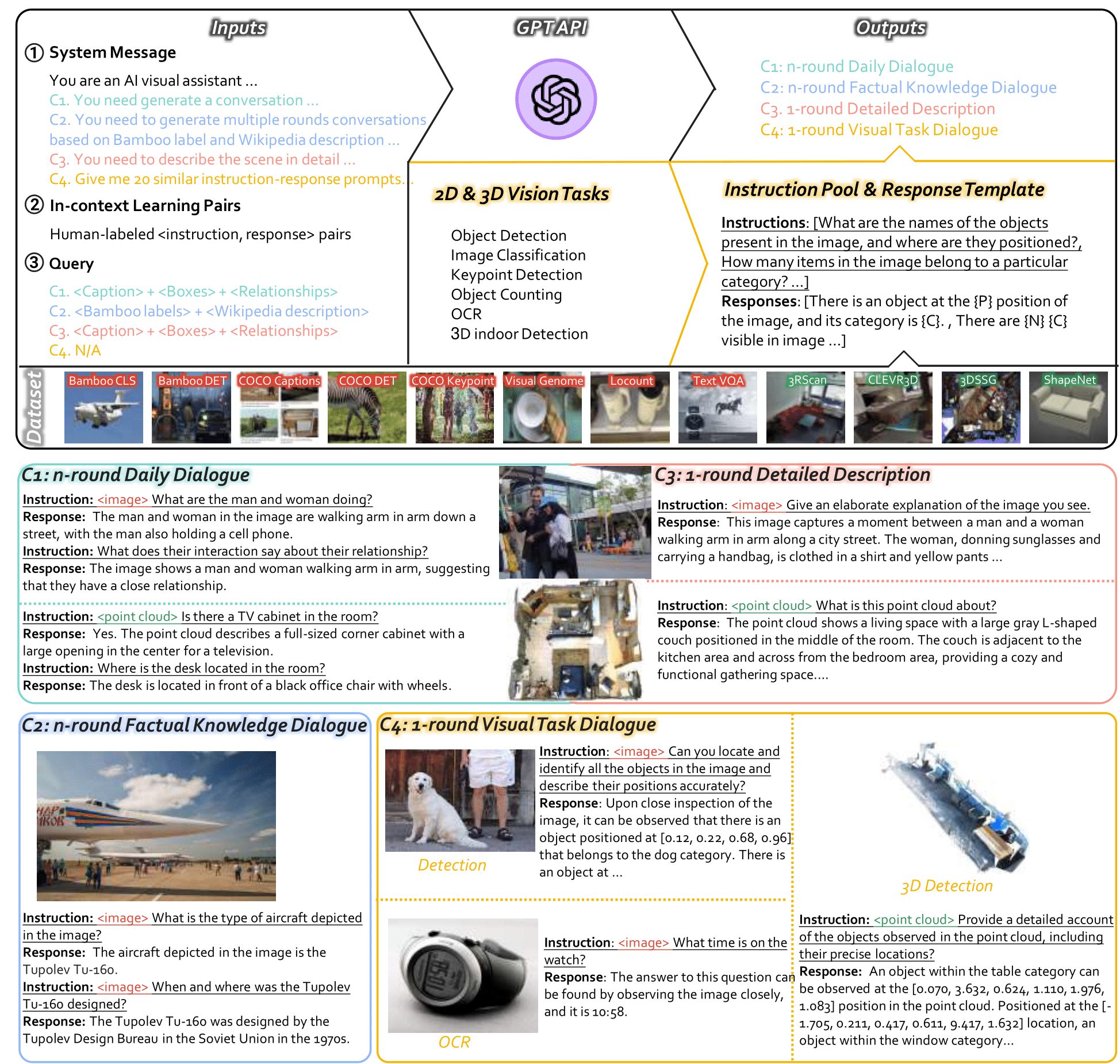
LAMM-Dataset is a comprehensive multi-modal instruction tuning dataset, which contains 186K language-image instruction-response pairs, and 10K lanuage-3D instruction-response pairs.In LAMM-Dataset, the instruction-response pairs are gathered from 8 image datasets and 4 point cloud datasets. Here we design four type of multi-modal instruction-response pairs,
- C1: n-round daily dialogue focuses on multi-modal daily conversations.
- C2: n-round factual knowledge dialogue aims at factual knowledge reasoning.
- C3: 1-round detailed description aims to elaborate images and 3D scenes in texts.
- C4: 1-round visual task dialogue transfers various vision tasks into instruction-response pairs, aiming at enhancing generalizability towards domain tasks in other modalities.
Octavius
Octavius additionally integrates generated COCO detection instruction data into original LAMM2D-Dataset as supplement in instruction tuning. For 3D point cloud data, Octavius constructs an novel instruction dataset based on the ScanRefer dataset that includes captioning, VQA and classification tasks, referred to as “Scan2Inst”, for 3D instruction tuning.
Benchmark Data
LAMM
LAMM-Benchmark evaluates 9 common image tasks, using a total of 11 datasets with over 62,439 samples, and 3 common point cloud tasks, by utilizing 3 datasets with over 12,788 data samples, while existing works only provide quantitative results on fine-tuning and evaluating specific datasets such as ScienceQA, and most works only conduct demonstration or user studies.
ChEF
ChEF evaluates MLLMs across 9 datasets including including CIFAR-10 for classification, Omnibenchmark for fine-grained classification, VOC2012 for object detection, FSC147 for object counting, Flickr30k for image captioning and ScienceQA for multimodal question-answering. We also evaluate the MLLMs on several multi-task datasets including MME, MMbench, and Seedbench. Based on ScienceQA and MMbench, we build ScienceQA_C and MMbench_C dataset by adding corruptions to images and text, to evaluate MLLM's Robustness, which is one of the six desiderata.