Tutorial
Tutorial
Our code is here.
Once you have successfully configured the environment, the entire directory structure should be as follows:
LAMM ├── ckpt │ ├── lamm_2d # saved checkpoints in training │ └── … ├── data # dataset folder, see
Dataset Preparationsection for detail │ ├── LAMM # LAMM dataset │ ├── Octavius # Octavius dataset │ ├── ChEF # ChEF dataset
│ └── … # your custom dataset ├── docs # document ├── images # readme assets ├── model_zoo # seeModel Preparation for Trainingfor detail │ ├── vicuna_ckpt # Vicuna-7B/13B │ ├── epcl_vit-L_256tokens # EPCL pretraining checkpoints (Optional) │ └── … ├── requirements # python environment requirements ├── src └── …
LAMM is one of the first open-source frameworks for Multi-modal Large Language Models (MLLMs) training and evaluation. Unlike frameworks such as LLaVA, LAMM specifically focuses on training and evaluating MLLMs for embodied agents.
Specifically, we have integrated data and code from a series of research projects, including:
- · Training and evaluation datasets for MLLMs supporting both 2D and 3D temporal data.
- · Training and evaluation code for MLLMs.
- · Implementation frameworks for embodied AI downstream tasks in both simulated environments (such as Minecraft) and real-world robotics manipulation scenarios.
For detailed information, please refer to our tutorials or specific research projects and documentation in the research section.
The framework provides a comprehensive solution for researchers and developers working at the intersection of multi-modal learning and embodied intelligence. Our goal is to facilitate the development and assessment of MLLMs that can effectively interact with and understand physical environments.
Training
Prepare Required Checkpoints
We provide pretrained weights of visual encoder and LLM. You can download them from the table below and place them in the model_zoo directory.
| Model Name | Link |
|---|---|
| Vicuna | Link |
| clip-vit-large-patch14-336 | Link |
| epcl_vit-L_256tokens | Link |
Organize the pretrained weights as below:
model_zoo ├── vicuna_ckpt │ ├── 13b_v0
│ └── 7b_v0 └── epcl_vit-L_256tokens
LAMM
- 2D Models Training
cd src sh tools/LAMM/train_lamm2d.sh lamm_2d # or sh tools/LAMM/train_lamm2d_slurm.sh <YOUR_PARTITION> lamm_2d - 3D Models Training
cd src sh tools/LAMM/train_lamm3d.sh lamm_3d # or sh tools/LAMM/train_lamm3d_slurm.sh <YOUR_PARTITION> lamm_3d
For your reference, GPU memory consumption for different models is shown as follows:
| Model Size | Sample Num/GPU | GPU Memory |
|---|---|---|
| Vicuna_v0_7B | 1 | ~30GB |
| Vicuna_v0_7B | 2 | ~46GB |
| Vicuna_v0_13B | 1 | ~53GB |
| Vicuna_v0_13B | 2 | ~70GB |
Octavius
- Image modality only
cd src sh tools/Octavius/train_octavius_slurm.sh <YOUR_PARTITION> <NUM_GPU> \ config/Octavius/octavius_2d_e4_bs64.yaml octavius_2d_e4_bs64 - Point cloud modality only
cd src sh tools/Octavius/train_octavius_slurm.sh <YOUR_PARTITION> <NUM_GPU> \ config/Octavius/octavius_3d_e3_bs64.yaml octavius_3d_e3_bs64 - Image & point cloud modality joint
cd src sh tools/Octavius/train_octavius_slurm.sh <YOUR_PARTITION> <NUM_GPU> \ config/Octavius/octavius_2d+3d_e6_bs64.yaml octavius_2d+3d_e6_bs64
Model Zoo
We provide several pretrained LAMM/Octavius checkpoints here:
LAMM Model Zoo
| # Training Samples | Vision Encoder | LLM | Training Data | Lora Rank | Link |
|---|---|---|---|---|---|
| 98K | CLIP-ViT-L | Vicuna_v0_7B | LAMM-2D daily dialogue & description | 32 | Checkpoints |
| 186K | CLIP-ViT-L | Vicuna_v0_7B | LAMM-2D Instruction Data | 32 | Checkpoints |
| 186K | CLIP-ViT-L | LLaMA2_chat_7B | LAMM-2D Instruction Data | 32 | Checkpoints |
| 98K | CLIP-ViT-L | Vicuna_v0_13B | LAMM-2D daily dialogue & description | 32 | Checkpoints |
| 186K | CLIP-ViT-L | Vicuna_v0_13B | LAMM-2D Instruction Data | 32 | Checkpoints |
| 10K | EPCL-ViT-L | Vicuna_v0_13B | LAMM-3D Instruction Data | 32 | Checkpoints |
Octavius Model Zoo
| #Samples | Vision Encoder | LLM | Training Data | Link |
|---|---|---|---|---|
| 286K | CLIP-ViT-L | Vicuna_v0_13B | LAMM-2D Instruction Data & COCO-Detection | ckpt |
| 90K | Obj-As-Scene | Vicuna_v0_13B | Scan2Inst | ckpt |
| 376K | CLIP-ViT-L & Obj-As-Scene | LLaMA2_chat_13B | LAMM-2D Instruction Data & COCO-Detection & Scan2Inst | ckpt |
You can download them and put them into the ckpt directory for fast evaluation.
Instruction Tuning
We construct instruction tuning dataset for 2D/3D modality instruction tuning via GPT API.
2D Instruction Tuning Datasets
2D instruction tuning datasets are build on MS-COCO, Bamboo, Locount and TextVQA dataset. You can download them from here.
The generated instruction-following dialogues are organized into the following meta files. We provide a table to illustrate the correspondence between each meta file and data collection:
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
daily_dialogue_49k.json | 112M | coco_images.zip | 7.8G |
detailed_description_49k.json | 83.2M | bamboo_images.zip | 5.4G |
vision_task_dialogue_46k.json | 64.8M | coco_images.zip, bamboo_images.zip, locount_images.zip, textvqa_images.zip | 9.2G |
LAMM_instruct_186k.json | 325M | / | / |
Note that we provide a LAMM_instruct_186k.json meta file to merge all the dataset across different tasks. You can just use this file for training.
Additional Detection Instruction
The lack of sufficient detection instructions results in poor performance on downstream PASCAL VOC evaluation. To overcome this problem, we leverage entire COCO detection annotations to generate instructions, and add them into the aforementioned datasets as supplementation.
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
coco_detection_117k.json | 116M | coco_images.zip | 7.8G |
octavius_2d_train_293k.json | 339M | / | / |
Note that we provide a LAMM_instruct_186k.json meta file to merge all the dataset across different tasks. You can just use this file for training.
3D Instruction Tuning Datasets
We provide two 3D instruction tuning datasets, “Scan2Inst” and “LAMM3D-Dataset”, for 3D instruction tuning.
Scan2Inst
Note: Compared with LAMM3D-Dataset, Scan2Inst provide more tasks and instruction-following dialogues, therefore we highly recommend you use Scan2Inst rather than LAMM3D-Dataset for 3D instruction tuning.
Scan2Inst is build on ScanNet. Specifically, we first use FCAF3D from mmdetection3d to extract 3d object given a scene level point cloud. Then a ULIP-like encoder is used to extract linguistic-aligned object level 3d feature. In the end, to speed up the data loading process, we store the dataset to a pickle file. For convincely, we provide a processed pickle file (scan2inst_train.pickle) here, you can train our model by just loading this file.
Besides, if you want to utilize your own dataset, we also provide our ULIP model pretraining code, you can train your own ULIP model by following the instructions from src/tools/Octavius/ULIP/scripts/pretrain_pointbert.sh. You can also use our pretrained model Here to extract your own dataset.
Corresponding meta file is here:
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
scan2inst_train.json | 62.3M | scan2inst_train.pickle | 209M |
LAMM3D-Dataset
LAMM3D-Dataset is build on 3RScan and ShapeNet. You can download them from here.
Corresponding meta file is here:
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
LAMM_3dinstruct_10k.json | 19.6M | 3rscan_pcls.zip, shapenet_pcls.zip | 929M |
Directory Structure
data ├── LAMM │ ├── 2D_Instruct
│ │ ├── coco_images.zip
│ │ ├── bamboo_images.zip
│ │ ├── textvqa_images.zip
│ │ ├── locount_images.zip
│ │ └── meta_file
│ │ ├── daily_dialogue_49k.json
│ │ ├── detailed_description_49k.json
│ │ ├── factual_knowledge_dialogue_42k.json
│ │ └── vision_task_dialogue_46k.json │ ├── 3D_Instruct │ │ ├── 3rscan_pcls.zip
│ │ ├── shapenet_pcls.zip
│ │ └── meta_file
│ │ └── LAMM_3dinstruct_10k.json │ └── … │ ├── Octavius │ ├── 2D_Instruct
│ │ ├── coco_images.zip
│ │ ├── bamboo_images.zip
│ │ ├── textvqa_images.zip
│ │ ├── locount_images.zip
│ │ └── meta_file
│ │ └── octavius_2d_train_293k.json │ ├── 3D_Instruct
│ │ ├── scan2inst_train.pickle │ │ └── meta_file
│ │ └── scan2inst_train.json
│ └── … │ └── …
Meta File Format
2D instruction tuning data
[
{
"id": "000000019028", # image id
"image": "coco_images/000000019028.jpg", # image path
"conversations": [
{
"from": "human", # instruction
"value": "How is the kitchen in the image furnished?"
},
{
"from": "gpt", # response
"value": "The kitchen in the image is furnished with white cabinets and white appliances. There is a dishwasher, a stove,
and a sink. On the stove, a blue towel hangs on the handle. A cutting board is placed on the dishwasher. There are also
additional elements like a bowl of apples on the counter and a beige rug on the floor."
}
],
"task_type": "conversation", # task type
"src_image": "coco2017" # original dataset
},
{
...
}
]
3D instruction tuning data
[
{
"pcl": "shapenet_pcls/04256520_cb71cb7b36dbcb6f826fc8d57346a2e4_4096.npy",
"conversations": [
{
"from": "human",
"value": "What scenario does this point cloud belong to according to the model\u2019s prediction?"
},
{
"from": "gpt",
"value": "Through meticulous analysis, it becomes evident that the point cloud aligns with the characteristics of sofa,
couch, lounge scenario."
}
],
"task_type": "classification3d",
"src_dataset": "ShapeNet",
"src_id": "04256520_cb71cb7b36dbcb6f826fc8d57346a2e4"
},
{
...
}
]
Benchmark
We provide 2D/3D/ChEF benchmarking datasets for downstream evaluation.
2D Benchmarking Datasets
2D Benchmarking datasets are build on Flickr30k, CIFAR-10, FSC147, CelebA, UCMerced, LSP, PASCAL VOC, SVT, AI2D and ScienceQA datasets. You can download them from here.
Corresponding meta file is here:
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
Caption_flickr30k.json | 598K | flickr30k_images.zip | 559M |
Classification_CIFAR10.json | 2.6M | cifar10_images.zip | 8.9M |
Counting_FSC147.json | 7.3M | fsc147_images.zip | 44M |
Detection_VOC2012.json | 6.4M | voc2012_images.zip | 196M |
Facial_Classification_CelebA(Hair).json | 2.4M | celeba_images.zip | 566M |
Facial_Classification_CelebA(Smile).json | 3.7M | celeba_images.zip | 566M |
Fine-grained_Classification_UCMerced.json | 676K | ucmerced_images.zip | 317M |
Keypoints_Dectection_LSP.json | 3.9M | lsp_images.zip | 44M |
Locating_FSC147.json | 7.5M | fsc147_images.zip | 44M |
Locating_LSP.json | 3.9M | lsp_images.zip | 9.9M |
Locating_VOC2012.json | 6.0M | voc2012_images.zip | 196M |
OCR_SVT.json | 68K | svt_images.zip | 82M |
VQA_AI2D.json | 2.1M | ai2d_images.zip | 559M |
VQA_SQAimage.json | 3.6M | sqaimage_images.zip | 127M |
3D Benchmarking Datasets
We provide two 3D benchmarking datasets, “Scan2Inst-benchmark” and “LAMM3D-Dataset-benchmark”.
Scan2Inst-benchmark
If your MLLMs are trained with “Scan2Inst”, you should use “Scan2Inst-benchmark” for evaluation.
We provide NR3D and ShapeNet for zero-shot evaluation, and ScanNet for finetuning evaluation. You can download processed pickle file from here.
Corresponding meta file is here:
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
| Caption_nr3d.json | 2.28M | Caption_nr3d.pickle | 25.41M |
| Caption_scannet.json | 239.43K | Caption_scannet.pickle | 7.29M |
| Classification_scannet.json | 249.80K | Classification_scannet.pickle | 7.38M |
| Classification_shapenet.json | 1.09M | Classification_shapenet.pickle | 21.45M |
| VQA_scannet.json | 231.64K | VQA_scannet.pickle | 4.82M |
LAMM3D-Dataset-benchmark
If your MLLMs are trained with “LAMM3D-Dataset”, you should use “LAMM3D-Dataset-benchmark” for evalution.
LAMM3D-Dataset-benchmark is build on ScanNet. You can download them from here.
Corresponding meta file is here:
| Meta file name | Size | Data file name | Size |
|---|---|---|---|
| Detection_ScanNet.json | 1.7M | scannet_pcls.zip | 246M |
| VG_ScanRefer.json | 3.7M | scannet_pcls.zip | 246M |
| VQA_ScanQA_multiplechoice.json | 859K | scannet_pcls.zip | 246M |
ChEF Benchmarking Dataset
Omnibenchmark
Download Omnibenchmark for fine-grained classification dataset and Bamboo Label System for hierarchical catergory labels.
We sampled and labeled Omnibenchmark meticulously by using a hierarchical chain of categories, facilitated by the Bamboo label system.
python ChEF/data_process/Omnibenchmark.py
You can also directly download the labeled Omnibenchmark dataset from OpenXLab.
MMBench, MME and SEEDBench
Refer to MMBench, MME and SEEDBench for dataset and more details.
POPE
POPE is a special labeled COCO dataset for hallucination evaluation based on the validation set of COCO 2014. Download COCO and POPE.
MMBench_C and ScienceQA_C
MMBench_C and ScienceQA_C are datasets with image and text corruptions fot robustness evaluation. You can also directly download the MMBench_C and ScienceQA_C dataset from OpenXLab.
Directory Structure
data ├── ChEF | │── Omnibenchmark_Bamboo
| │ ├── meta_file | │ └── omnibenchmark_images | ├── MMBench_C | | ├── images | | ├── Image_Corruptions_info.json | | ├── Text_Corruptions_info.json | | └── MMBench_C.json | └── ScienceQA_C | ├── sqaimage_images | ├── Image_Corruptions_info.json | ├── Text_Corruptions_info.json | └── VQA_ScienceQA_C.json ├── Bamboo | └── sensexo_visual_add_academic_add_state_V4.visual.json |── MMBench | ├── mmbench_dev_20230712.tsv | └── mmbench_test_20230712.tsv |── MME_Benchmark_release_version |── SEED-Bench |── coco_pope | ├── val2014 | ├── coco_pope_adversarial.json | ├── coco_pope_popular.json | └── coco_pope_random.json └── …
Installation
Training
Pre-requist Packages:
gcc <= 7.5.0; nvcc >= 11.1
Python & Pytorch Environment
conda create -n lamm python=3.10 -y
conda activate lamm
# Choose different version of torch according to your
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
Install Required Dependencies
conda install timm==0.6.7 deepspeed==0.9.3 transformers==4.31.0 -c conda-forge
pip install peft==0.3.0 --no-dependencies
pip install -r requirements/default.txt
Install Faiss
# if cuda is available
conda install -c conda-forge faiss-gpu
# otherwise
conda install -c conda-forge faiss-cpu
Download required NLTK data
import nltk
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('wordnet')
Optional Dependencies
LAMM-3D Environments
cd src/model/EPCL/third_party/pointnet2/
python setup.py install
cd ../../utils/
pip install cython
python cython_compile.py build_ext --inplace
Reducing Memory in Training
· flash attention (v2)
Install flash attention (v2) if you are tight in GPU memory. Please refer to flash attention’s installation
FlashAttention-2 currently supports Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100).
· xformers
Install xformers if you are tight in GPU memory and cannot use flash attention (e.g., using Nvidia v100). Please refer to xformers’s installation
Benchmarking
We use ChEF for benchmarking.
conda create -n ChEF python=3.10
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install -r requirements/default.txt
pip install -r requirements/ChEF.txt
Optional Dependencies
Efficient Inference
· lightllm
Install lightllm to speed up inference and decrease the GPU memery usage to enable large batchsize.
git clone -b multimodal https://github.com/ModelTC/lightllm.git
cd lightllm
python setup.py install
Default Benchmark
LAMM-Benchmark
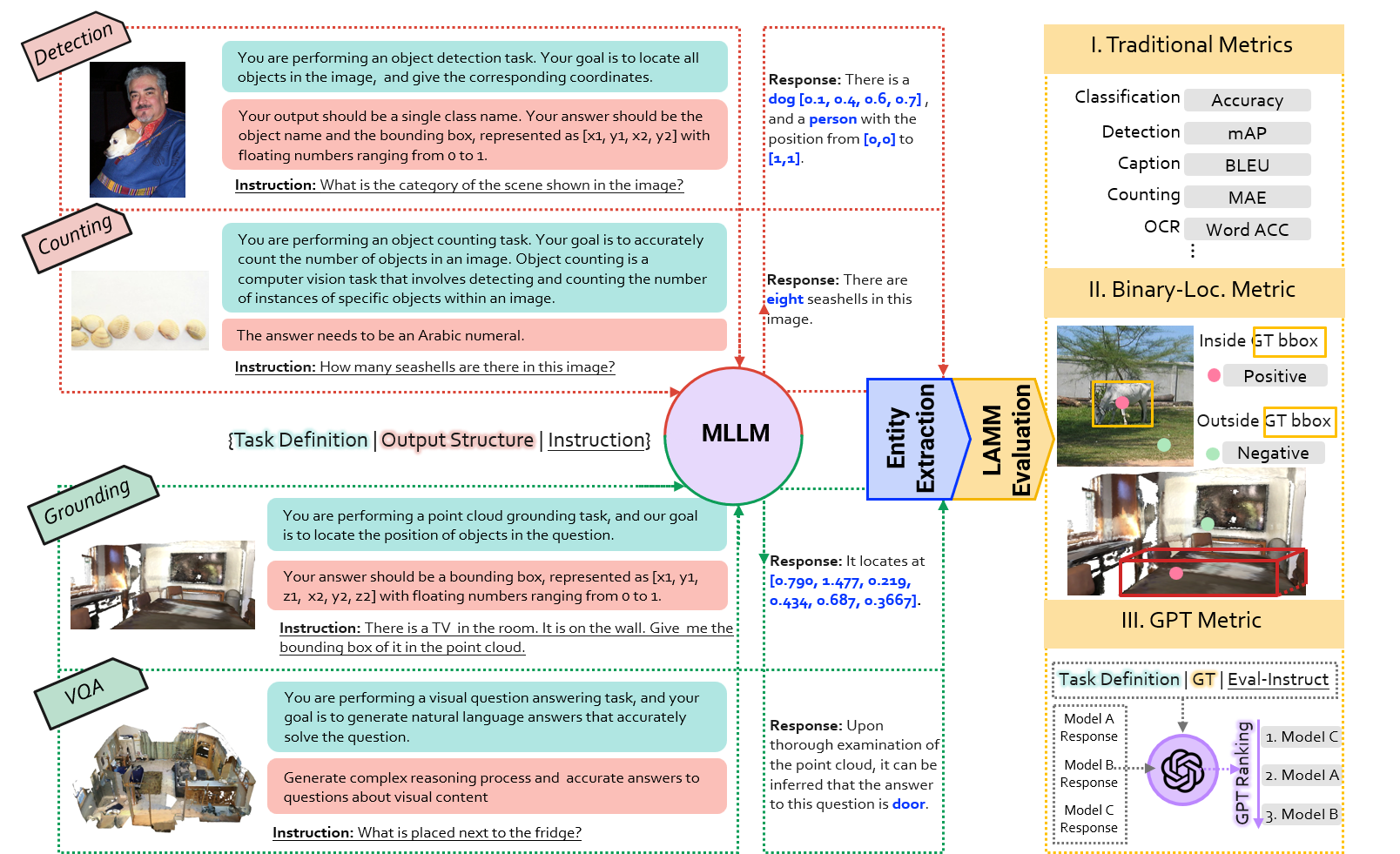
Notes: LAMM-Benchmark has now been fully implemented using ChEF, and we highly recommend using the latest ChEF evaluation method for benchmarking in your work. ChEF supports the common 2D and 3D tasks evaluation and locating tasks evaluation in LAMM. Please note that the GPT rank metric in LAMM is no longer applicable.
To evaluate LAMM/Octavius on LAMM-Benchmark in 2D common tasks, use the pre-defined model config (src/config/ChEF/models/lamm.yaml or src/config/ChEF/models/octavius_2d+3d.yaml) and the pre-defined recipes config (src/config/ChEF/scenario_recipes/LAMM/).
python eval.py --model_cfg config/ChEF/models/lamm.yaml --recipe_cfg config/ChEF/scenario_recipes/LAMM/ScienceQA.yaml
If you want to automately running all the evaluations sequentially, you can run
sh tools/LAMM/eval_lamm2d.sh
sh tools/LAMM/eval_lamm3d.sh
To evaluate Octavius on ScanNet Detection, run:
sh tools/Octavius/octavius_ChEF.sh
ChEF
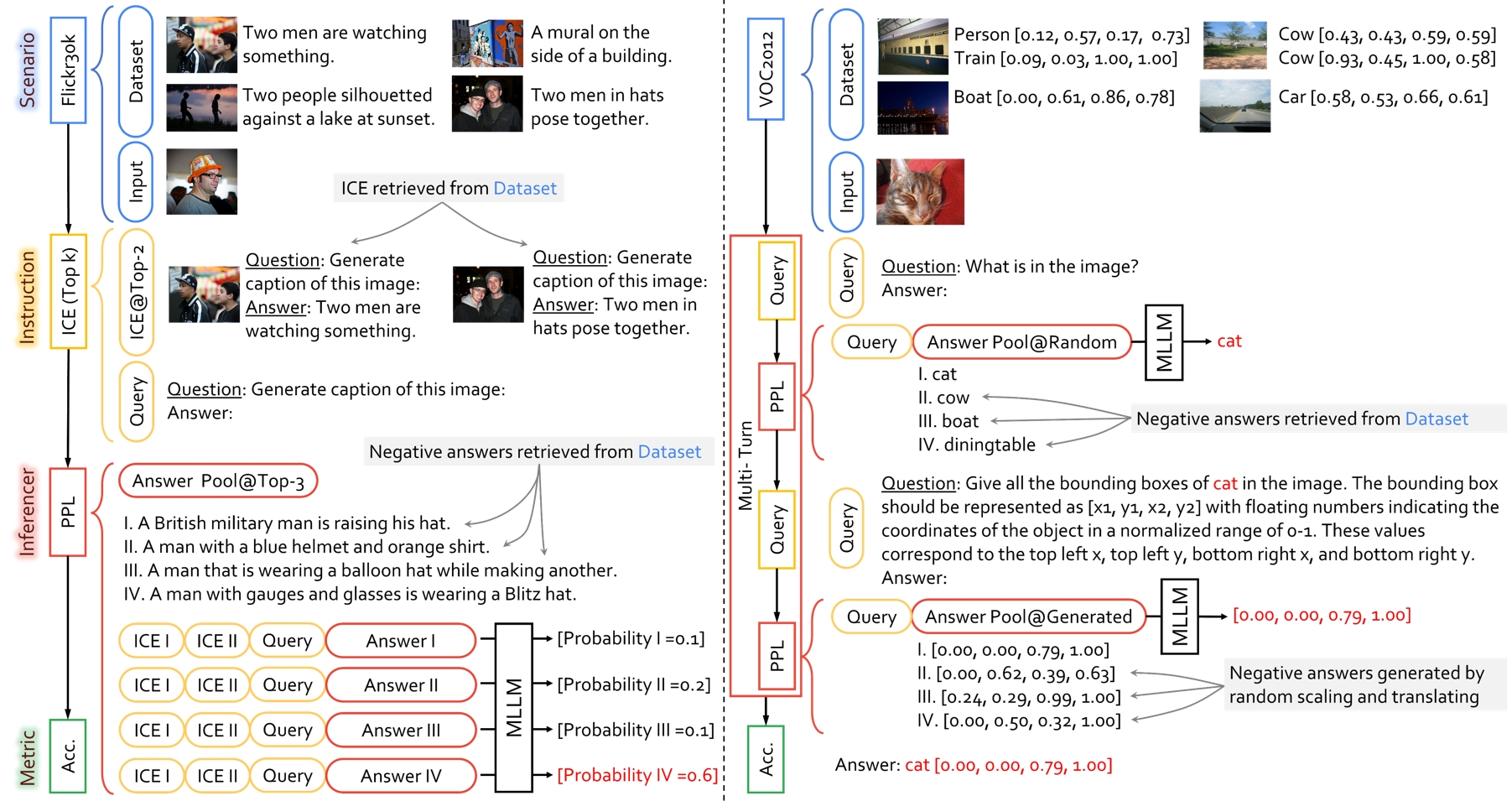
Download Evaluated MLLMs
| LLM | Vision Encoder | Language Model | Link |
|---|---|---|---|
| InstructBLIP | EVA-G | Vicuna 7B | instruct_blip_vicuna7b_trimmed |
| Kosmos2 | CLIP ViT-L/14 | Decoder 1.3B | kosmos-2.pt |
| LAMM | CLIP ViT-L/14 | Vicuna 13B | lamm_13b_lora32_186k |
| LLaMA-Adapter-v2 | CLIP ViT-L/14 | LLaMA 7B | LORA-BIAS-7B |
| LLaVA | CLIP ViT-L/14 | MPT 7B | LLaVA-Lightning-MPT-7B |
| MiniGPT-4 | EVA-G | Vicuna 7B | MiniGPT-4 |
| mPLUG-Owl | CLIP ViT-L/14 | LLaMA 7B | mplug-owl-llama-7b |
| Otter | CLIP ViT-L/14 | LLaMA 7B | OTTER-9B-LA-InContext |
| Shikra | CLIP ViT-L/14 | LLaMA 7B | shikra-7b |
Organize them as below:
ckpt ├── epcl_vit-L_256tokens ├── │ ├── lamm_2d # saved checkpoints in training │ └── … └── …
Custom Benchmark
Evaluator
In ChEF, all evaluation pipelines are managed by the Evaluator (src/ChEF/evaluator.py) class. This class serves as the control center for evaluation tasks and incorporates various components, including a scenario, an instruction, an inferencer, and a metric. These components are defined through recipe configurations.
Key Components:
- · Scenario: The scenario represents the evaluation dataset and task-specific details.
- · Instruction: Responsible for processing samples and generating queries.
- · Inferencer: Performs model inference on the dataset.
- · Metric: Evaluates model performance using defined metrics.
Evaluation Workflow
The evaluation process in ChEF follows a structured workflow:
- · Model and Data Loading: First, the model and evaluation dataset (scenario) are loaded.
- · Evaluator.evaluate Method: The evaluation is initiated by calling the
evaluatemethod of theEvaluatorclass. - · Inference with inferencer.inference: The
inferenceris used to perform model inference. During dataset traversal, theInstructionHandlerprocesses each sample, generating queries that serve as inputs to the model. - · Results Saving: The output of the inference is saved in the specified
results_path. - · Metric Evaluation: Finally, the
metricevaluates the results file, calculating various performance metrics specific to the evaluation task. - · Output Evaluation Results: The final evaluation results are provided as output, allowing you to assess the model’s performance.
Employ Your Model
In ChEF, you can employ your own custom models by following these steps:
Step 1: Prepare Your Model Files
- · Navigate to the
src/ChEF/models/folder in ChEF. - · Paste all the necessary files for your custom model into this folder.
Step 2: Write the Test Model
- · Create a new Python file in the models folder and name it something like
test_your_model.py. - · In this file, you will need to inherit from the
TestBaseclass defined insrc/ChEF/models/test_base.py. TheTestBaseclass provides a set of interfaces that you should implement for testing your model.
Step 3: Test Your Model
- · Add your model in
src/ChEF/models/init.py. - · Prepare your model configuration in
src/config/ChEF/models/. For example, the config forKOSMOS-2(src/config/ChEF/models/kosmos2.yaml):
model_name: Kosmos2
model_path: ../model_zoo/kosmos/kosmos-2.pt
if_grounding: False # set True for detection and grounding evaluation
The config for KOSMOS-2 on detection tasks evaluation:
model_name: Kosmos2
model_path: ../model_zoo/kosmos/kosmos-2.pt
if_grounding: True
Use the provided recipes for evaluation:
python tools/eval.py --model_cfg configs/ChEF/models/your_model.yaml --recipe_cfg recipe_cfg
Instruction
In ChEF, the InstructionHandler (src/ChEF/instruction/init.py) class plays a central role in managing instructions for generating queries when iterating through the dataset in the inferencer. These queries are then used as inputs to the model for various tasks.
ChEF supports three main query types: standard query, query pool, and multiturn query. For each query type, various query statements are defined based on the dataset’s task type.
- · Standard Query: Uses the first query defined in the query pool.
- · Query Pool: Specifies queries in the pool by assigned ids defined in the configuration.
- · Multiturn Query: Can get different queries depending on the turn id, which are also defined in the query pool.
For more details, refer to the src/ChEF/instruction/query.py.
InstructionHandler also supports generating in-context examples for queries using ice_retriever (src/ChEF/instruction/ice_retriever/). ChEF supports four types of ice_retrievers: random, fixed, topk_text, and topk_img. The generate_ices function in the InstructionHandler class outputs several in-context examples for the input query.
Employ Your Instruction: You can add special queries in the Query Pool, and define the assigned ids in the recipe configuration to use the new queries. You can also define a new type of query by defining the query in src/ChEF/instruction/query.py and adding a new function in InstructionHandler.
Inferencer
In ChEF, the Inferencer component is a crucial part of the system, responsible for model inference. ChEF offers a variety of pre-defined inferencers to cater to different needs. You can easily choose the appropriate inferencer by specifying the inferencer category and necessary settings in the recipe configuration. Additionally, users have the flexibility to define their custom inferencers.
Pre-Defined Inferencers:
ChEF provides eight different inferencers that cover a range of use cases. You can effortlessly use the desired inferencer by specifying its category and required settings in the recipe configuration.
Custom Inferencers:
For advanced users and specific requirements, ChEF offers the option to create custom inferencers. The basic structure of an inferencer is defined in the src/ChEF/inferencer/Direct.py file (Direct_inferencer). You can extend this structure to implement your custom inferencer logic.
class Your_inferencer(Direct_inferencer):
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
def inference(self, model, dataset):
predictions = []
# Step 1: build dataloader
dataloader = DataLoader(dataset, batch_size=self.batch_size, collate_fn=lambda batch: {key: [dict[key] for dict in batch] for key in batch[0]})
for batch in tqdm(dataloader, desc="Running inference"):
# Step 2: get input query
prompts = self.instruction_handler.generate(batch)
# Step 3: model outputs
outputs = model.generate(prompts)
# Step 4: save results
predictions = predictions + outputs
# Step 5: output file
self._after_inference_step(predictions)
Metric
In ChEF, the Metric component plays a crucial role in evaluating and measuring the performance of models across various scenarios and protocols. ChEF offers a wide range of pre-defined metrics, each tailored to different evaluation needs. Detailed information about these metrics can be found in the src/ChEF/metric/init.py file.
Custom Metrics:
ChEF also allows users to define their custom metrics. The basic structure of a metric is defined in the src/ChEF/metric/utils.py file (Base_Metric). You can extend this structure to implement your custom metric logic.
class Your_metric(Base_metric):
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
def metric_func(self, answers):
'''
answers: List[sample], each sample is a dict
sample: {
'answer' : str,
'gt_answers' : str,
}
'''
# Evaluation
LAMM
@article{yin2023lamm,
title={LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark},
author={Yin, Zhenfei and Wang, Jiong and Cao, Jianjian and Shi, Zhelun and Liu, Dingning and
Li, Mukai and Sheng, Lu and Bai, Lei and Huang, Xiaoshui and Wang, Zhiyong and others},
journal={arXiv preprint arXiv:2306.06687},
year={2023}
}
ChEF
@misc{shi2023chef,
title={ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal
Large Language Models},
author={Zhelun Shi and Zhipin Wang and Hongxing Fan and Zhenfei Yin and Lu Sheng and Yu Qiao
and Jing Shao},
year={2023},
eprint={2311.02692},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Octavius
@misc{chen2023octavius,
title={Octavius: Mitigating Task Interference in MLLMs via LoRA-MoE},
author={Zeren Chen and Ziqin Wang and Zhen Wang and Huayang Liu and Zhenfei Yin and Si Liu
and Lu Sheng and Wanli Ouyang and Yu Qiao and Jing Shao},
year={2023},
eprint={2311.02684},
archivePrefix={arXiv},
primaryClass={cs.CV}
}