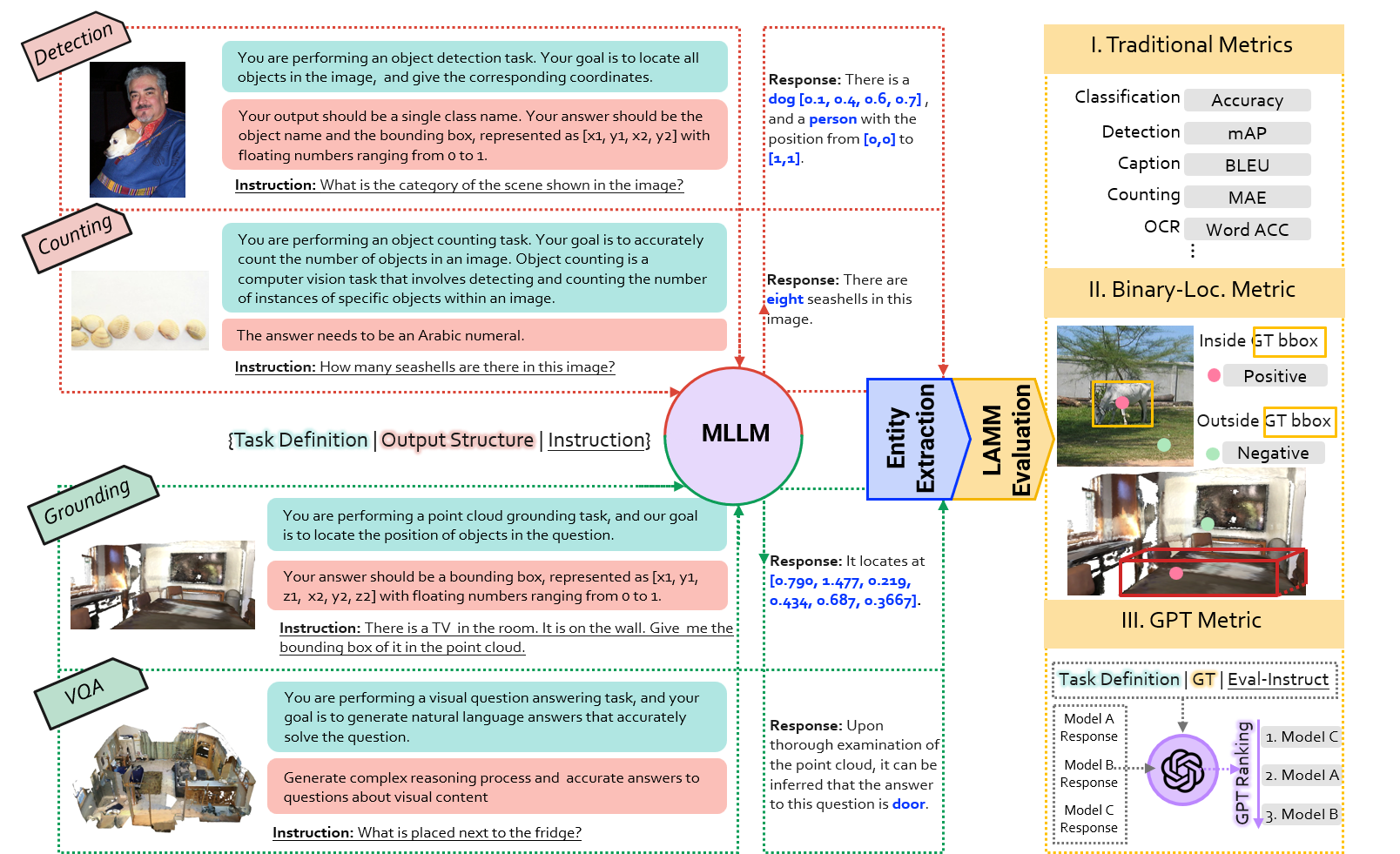
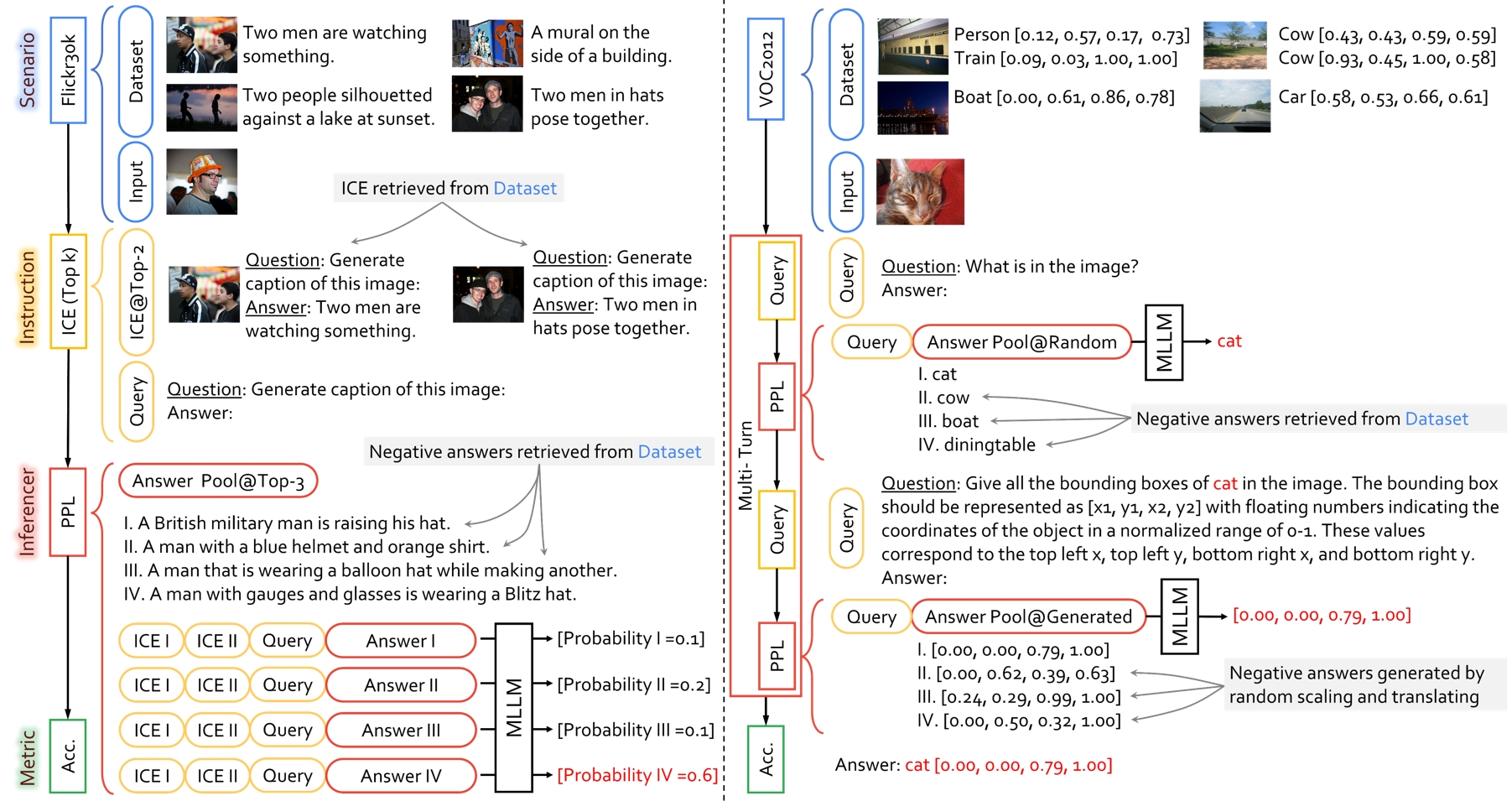
Notes: LAMM-Benchmark has now been fully implemented using ChEF, and we highly recommend using the latest ChEF evaluation method for benchmarking in your work. ChEF supports the common 2D and 3D tasks evaluation and locating tasks evaluation in LAMM. Please note that the GPT rank metric in LAMM is no longer applicable.
To evaluate LAMM/Octavius on LAMM-Benchmark in 2D common tasks, use the pre-defined model config (src/config/ChEF/models/lamm.yaml or src/config/ChEF/models/octavius_2d+3d.yaml) and the pre-defined recipes config (src/config/ChEF/scenario_recipes/LAMM/).
python eval.py --model_cfg config/ChEF/models/lamm.yaml --recipe_cfg config/ChEF/scenario_recipes/LAMM/ScienceQA.yaml
If you want to automately running all the evaluations sequentially, you can run
sh tools/LAMM/eval_lamm2d.sh
sh tools/LAMM/eval_lamm3d.sh
To evaluate Octavius on ScanNet Detection, run:
sh tools/Octavius/octavius_ChEF.sh
| LLM | Vision Encoder | Language Model | Link |
|---|---|---|---|
| InstructBLIP | EVA-G | Vicuna 7B | instruct_blip_vicuna7b_trimmed |
| Kosmos2 | CLIP ViT-L/14 | Decoder 1.3B | kosmos-2.pt |
| LAMM | CLIP ViT-L/14 | Vicuna 13B | lamm_13b_lora32_186k |
| LLaMA-Adapter-v2 | CLIP ViT-L/14 | LLaMA 7B | LORA-BIAS-7B |
| LLaVA | CLIP ViT-L/14 | MPT 7B | LLaVA-Lightning-MPT-7B |
| MiniGPT-4 | EVA-G | Vicuna 7B | MiniGPT-4 |
| mPLUG-Owl | CLIP ViT-L/14 | LLaMA 7B | mplug-owl-llama-7b |
| Otter | CLIP ViT-L/14 | LLaMA 7B | OTTER-9B-LA-InContext |
| Shikra | CLIP ViT-L/14 | LLaMA 7B | shikra-7b |
Organize them as below:
ckpt ├── epcl_vit-L_256tokens ├── │ ├── lamm_2d # saved checkpoints in training │ └── … └── …