Zhelun Shi*,1,2 Zhipin Wang*,1 Hongxing Fan*,1 Zhenfei Yin2
Lu Sheng†,1 Yu Qiao2 Jing Shao†,2
1Beihang University 2Shanghai AI Laboratory
* Equal Contribution † Corresponding Author
Introduction
ChEF is a Comprehensive Evaluation Framework for reliable and indicative assessment of MLLMs, which is highly scalable and can be flexibly modified to adapt to the evaluation of any new model or task.
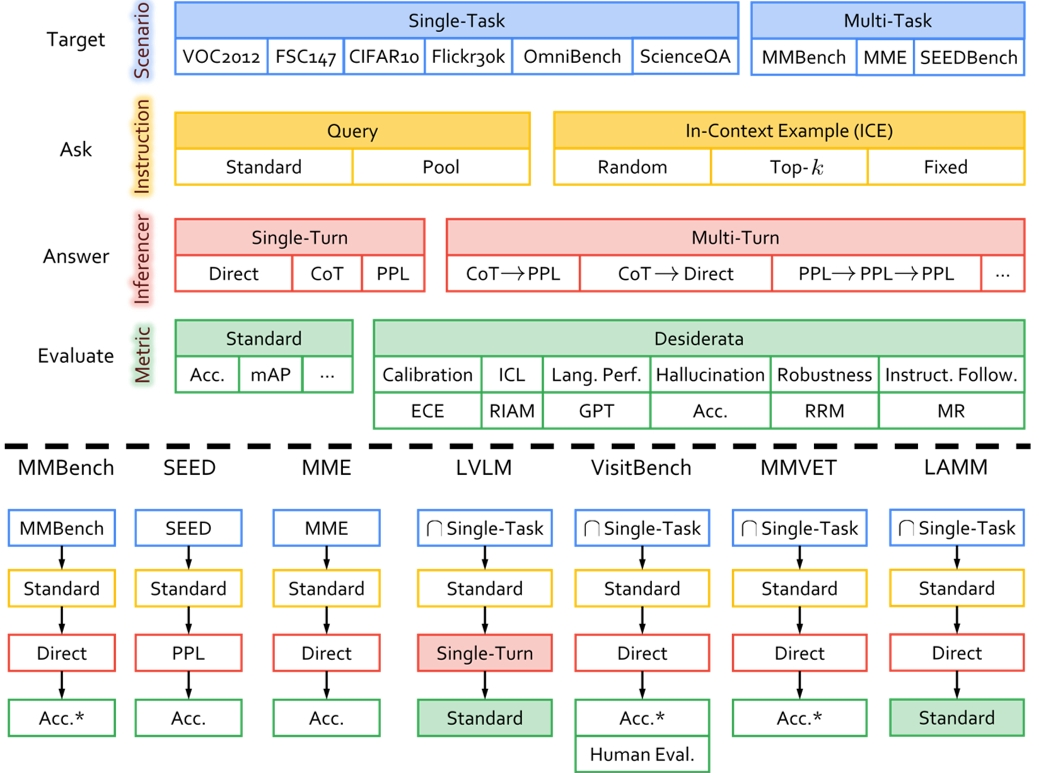
ChEF decouples the evaluation pipeline into four components:
- Scenario: A set of datasets concerning representative multimodal tasks that are suitable for MLLMs.
- Instruction: The module of posing questions and setting instruction examples to the MLLMs.
- Inferencer: Strategies for MLLMs to answer questions.
- Metric: Score functions designed to evaluate the performance of MLLMs.
With a systematic selection of these four componets, ChEF facilitates versatile evaluations in a standardized framework. Users can easily build new evaluations according to new Recipes (i.e. specific choices of the four components). ChEF also sets up several new evaluations to quantify the Desiderata (desired capabilities) that a competent MLLM model should possess.
Supported Scenarios and MLLMs
Scenarios:
MLLMs:
Usage
Environment installation.
Prepare the benchmark dataset and evalauted MLLMs.
Evaluation ChEF supports evaluation with several scenarios and recipes for MLLMs. See here for details.
Custom Evaluation You can customize the behavior of Evaluator in ChEF for your requirements. See here for details.
Citation
@misc{shi2023chef,
title={ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models},
author={Zhelun Shi and Zhipin Wang and Hongxing Fan and Zhenfei Yin and Lu Sheng and Yu Qiao and Jing Shao},
year={2023},
eprint={2311.02692},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
License
The project is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.